SQLのテーブル結合は、以下の3種類の方法があります。
取得したいデータの内容によって、結合の方法を使い分ける必要があります。
今回は、3種類の結合方法についてPostgreSQLを使って解説していきます。
環境情報
テーブル定義と格納データ
解説で使用するテーブル定義と格納データは以下になります。
『役職テーブル』と『社員テーブル』の、2つのテーブルを想定します。
create table yakusyoku (
yakusyoku_id serial not null
, yakusyoku_name varchar(10) not null
, constraint yakusyoku_pkey primary key (yakusyoku_id)
) ;
create table syain (
syain_id serial not null
,yakusyoku_id integer
, syain_name varchar(10) not null
, constraint syain_pkey primary key (syain_id)
) ;
"yakusyoku_id" "yakusyoku_name"
-----------------------------------
1 "部長"
2 "課長"
3 "係長"
4 "主任"
"syain_id" "yakusyoku_id" "syain_name"
----------------------------------------------
1 1 "山田部長"
2 2 "鈴木課長"
3 3 "佐藤係長"
4 3 "佐藤係長"
内部結合/依存関係ありのデータを取得する
内部結合は、依存関係(レコード間のリレーション)があるデータのみを取得します。
今回の例では、役職が付いている社員のみが取得するSQLを実現することができます。
SELECT
A.yakusyoku_id
A.yakusyoku_name
B.syain_id
B.syain_name
FROM
yakusyoku as A INNER JOIN syain as B
ON
A.yakusyoku_id = B.yakusyoku_id;
"yakusyoku_id" "yakusyoku_name" "syain_id" "syain_name"
-----------------------------------------------------------
1 "部長" 1 "山田部長"
2 "課長" 2 "鈴木課長"
3 "係長" 3 "佐藤係長"
3 "係長" 4 "佐藤係長"
外部結合/依存関係なしのデータも取得する
内部結合は、依存関係がないデータのみも取得します。
今回の例では、主任の社員はいないのですが、役職テーブルのメインテーブルとして外部結合をおこなっているので、主任レコードも取得できます。
SELECT
A.yakusyoku_id
A.yakusyoku_name
B.syain_id
B.syain_name
FROM
yakusyoku as A LEFT OUTER JOIN syain as B
ON
A.yakusyoku_id = B.yakusyoku_id;
"yakusyoku_id" "yakusyoku_name" "syain_id" "syain_name"
-----------------------------------------------------------------
1 "部長" 1 "山田部長"
2 "課長" 2 "鈴木課長"
3 "係長" 3 "佐藤係長"
3 "係長" 4 "佐藤係長"
4 "主任" "" ""
クロス結合/組み合わせを取得する
クロス結合の基本文法
クロス結合は、レコード同士の組み合わせを取得します。
今回の例では、全ての役職と全ての社員の組み合わせを取得できます。
結合条件も指定しないので、役職テーブルの主任レコードに対する組み合わせについても取得できます。
SELECT
A.yakusyoku_id
A.yakusyoku_name
B.syain_id
B.syain_name
FROM
yakusyoku as A CROSS JOIN syain as B;
"yakusyoku_id" "yakusyoku_name" "syain_id" "syain_name"
--------------------------------------------------------------
1 "部長" 1 "山田部長"
1 "部長" 2 "鈴木課長"
1 "部長" 3 "佐藤係長"
1 "部長" 4 "佐藤係長"
2 "課長" 1 "山田部長"
2 "課長" 2 "鈴木課長"
2 "課長" 3 "佐藤係長"
2 "課長" 4 "佐藤係長"
3 "係長" 1 "山田部長"
3 "係長" 2 "鈴木課長"
3 "係長" 3 "佐藤係長"
3 "係長" 4 "佐藤係長"
4 "主任" 1 "山田部長"
4 "主任" 2 "鈴木課長"
4 "主任" 3 "佐藤係長"
4 "主任" 4 "佐藤係長"
クロス結合の使いどころ。横→縦変換
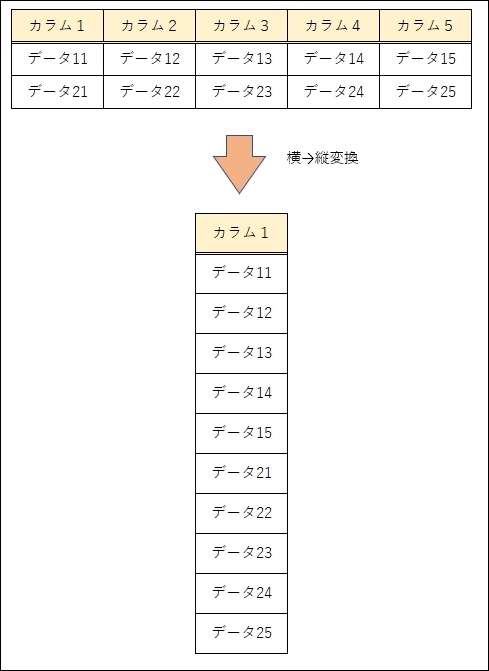
クロスジョインはあまり用途がないように思いますが、よく使う用途としては横→縦変換になります。
横→縦変換とは、カラム毎に格納されている値をレコード事に格納することです。
以下のようなイメージですね。
以下に具体的を使って説明しています。
テーブルの横→縦変換をおこなってみます。
create table col_test (
col_test_id serial not null
, name1 varchar(10) not null
, name2 varchar(10) not null
, name3 varchar(10) not null
, name4 varchar(10) not null
, name5 varchar(10) not null
, constraint col_test_id_pkey primary key (col_test_id)
) ;
"name1", "name2", "name3", "name4", "name5"
--------------------------------------------------------------
1, "名称1_A", "名称2_B", "名称3_C", "★名称4_D","名称5_E"
2, "★名称1_B","名称2_B", "名称3_B", "名称4_B", "名称5_B"
3, "名称1_C", "★名称2_C","★名称3_C","名称4_C", "名称5_C"
このテーブルから、名称の先頭に「★」が付いている値を行データとして取得するとします。 この場合、縦→横変換をおこなうと便利です。
縦→横変換をおこなうために、テンポラリテーブル(TEMPORARY TABLE)
を使っています。
テンポラリテーブルで、1~5の値が入っているのみのテーブルを作成しています。
このテンポラリテーブルと対象テーブル(ここではpivot)をCROSS JOINを使って組み合わせを作成し、その組み合わせで名称の先頭に「★」ついているレコードのみを取得しています。
-- テンポラリテーブルの作成
CREATE TEMPORARY TABLE pivot (
val integer PRIMARY KEY
);
-- テンポラリテーブルに1~5の値が入った状態にする
INSERT INTO pivot with recursive rec(val) as (
values(1)
union all
select
Val+1
from
rec
where
Val+1 <= 5
) select Val from rec;
-- 名称の先頭に「★」がついたレコードのみを抽出
SELECT * FROM (
SELECT
case P.val
when 1 then A.name1
when 2 then A.name2
when 3 then A.name3
when 4 then A.name4
when 5 then A.name5
end as cross
FROM
col_test as A CROSS JOIN pivot P) AS X
WHERE
X.cross like '★%';
"cross"
-------------------
★名称1_B
★名称2_C
★名称3_C
★名称4_D