apt install curl ca-certificates gnupg
curl https://www.postgresql.org/media/keys/ACCC4CF8.asc | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/apt.postgresql.org.gpg >/dev/null
sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
cat /etc/apt/sources.list.d/pgdg.list
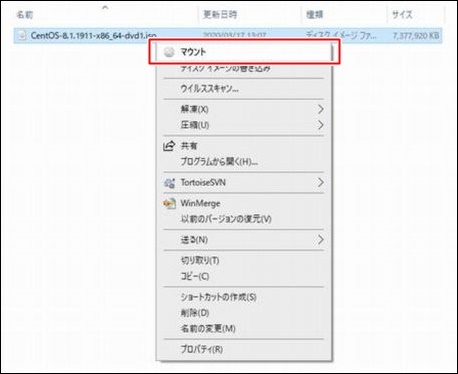
↓レポジトリが追加されていることを確認
deb http://apt.postgresql.org/pub/repos/apt jammy-pgdg main
↑レポジトリが追加されていることを確認
apt update
apt info postgresql
↓標準バージョンが変化していることを確認
Package: postgresql
Version: 15+253.pgdg22.04+1
↑標準バージョンが変化していることを確認
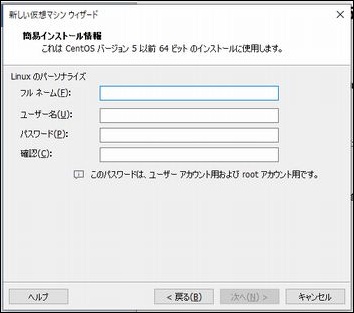
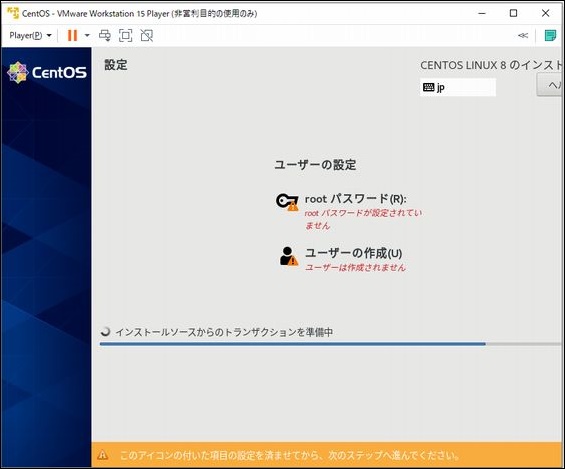
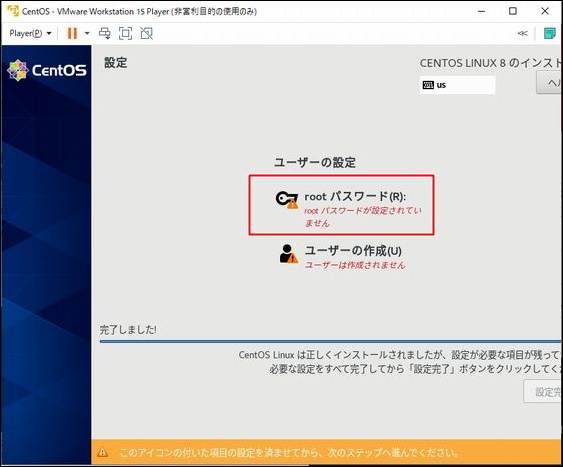
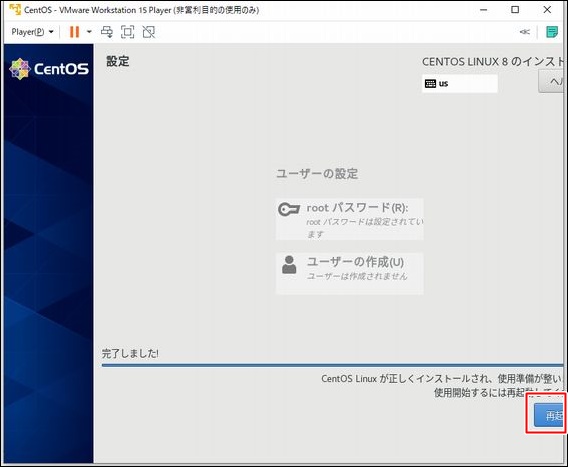
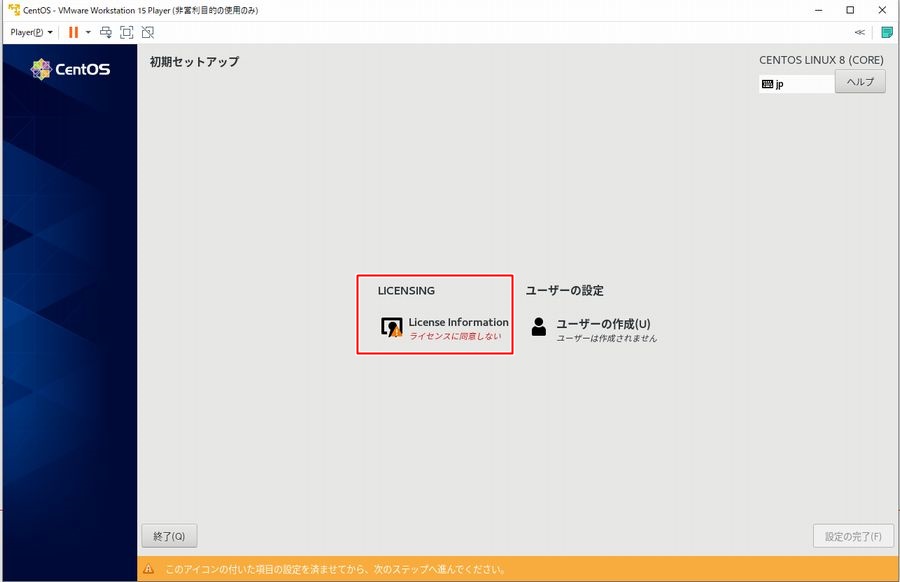
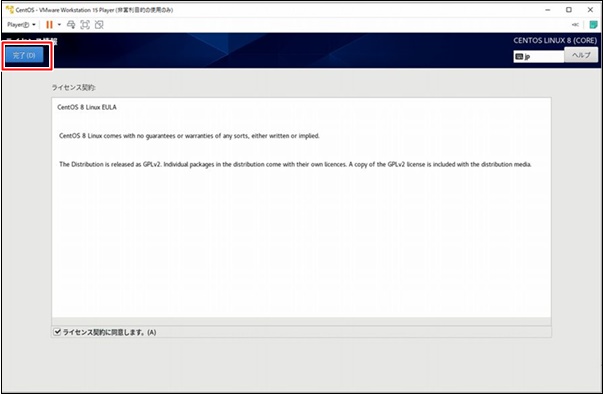
PostgreSQLをインストール
とりあえずPostgreSQLをインストールしてみます。
apt install -y postgresql
以下のメッセージが表示されてエラーとなります。
E: Failed to fetch http://apt.postgresql.org/pub/repos/apt/pool/main/p/postgresql-15/postgresql-15_15.4-1.pgdg22.04%2b1_amd64.deb Connection failed [IP: 87.238.57.227 80]
E: Unable to fetch some archives, maybe run apt-get update or try with --fix-missing?
E: Failed to fetch http://apt.postgresql.org/pub/repos/apt/pool/main/p/postgresql-15/postgresql-15_15.4-1.pgdg22.04%2b1_amd64.deb Connection failed [IP: 147.75.85.69 80]
E: Unable to fetch some archives, maybe run apt-get update or try with --fix-missing?
MySQLに、現在接続しているコネクション数を確認するには、show status コマンドを実行します。 MySQLにログインしてコマンドを実行します。
mysql> show status like 'Threads_connected';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_connected | 29 |
+-------------------+-------+
1 row in set (0.00 sec)
mysql> SHOW GLOBAL VARIABLES like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 512 |
+-----------------+-------+
1 row in set (0.01 sec)
mysql> SHOW processlist;
+------------+------------+------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+------------+------------+---------------------+--------+
・
・
・
mysql> show global status like 'Max_used_connections';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| Max_used_connections | 513 |
+----------------------+-------+
1 row in set (0.00 sec)
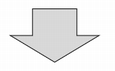
$ tail -F file1.txt
tail: `file1.txt' has become inaccessible: No such file or directory
tail: `file1.txt' has appeared; following end of new file
tail: file1.txt: file truncated
ファイル1
ファイル2
ファイル3