
文書を管理するシステムの場合、文書の中身を検索する機能が必要だったりします。
例えば、”システムに登録されているWordファイルについて、「○△□」といった文字が存在するファイルだけ注出する”といった機能です。
でも、そういった機能をゼロから作るのは大変ですよね。
プログラムを作るとしたら、”ファイルを開いて”→ “ファイルの中身の文字を注出して”→”キーワードと一致する文字を検索して”といった作り込みが必要です。
今回は、Apache SolrをJavaから呼び出し、文書を登録、編集、削除する方法を説明していきます。
『Apache Solr』を導入すると、文書の管理(登録、編集、削除)や文書の検索をAPI形式で実行することができ、簡単に文書管理をおこなうシステムを構築することができます。
- 文書の管理(登録、編集、削除)
- 文書の検索
- 文書検索結果の返却
今回は、Apache Solrの開発環境構築から、JavaからAPIを呼び出して結果を取得するまでを紹介します。
Apache Solrのインストール(サービス化)
まずは、Apache Solrをインストールします。
今回は、Apache Solrをサービス化する形でインストールします。
サービス化は、「nssm」を使用します。
nssmは、Microsoft Windows用のサービスマネージャです。
サービス化すると、バックグラウンドおよびフォアグラウンドのサービスとプロセスを管理する無料のユーティリティです。 プログラムは、失敗したサービスを自動的に再始動するように設定できます。
以下サイトからダウンロード可能です。

という訳で、環境情報としては以下になります。
- 文書検索エンジン:Apache Solr 6.4.2
- サービス化ツール:nssm 2.24
公式サイトからダウンロードしたApache Solrのモジュールとnssmを、任意のフォルダに配置します。
筆者は、Apache Solrを「C:\ApacheSolr」直下に、nssmを「C:\SolrInstall」に配置しました。
以下のような感じです。
Apache Solrの”インストール”というのは不要で、マシンに配置して完了です。
nssmを使用して、配置したApache Solrをサービス化します。
それでは、nssmでのサービス化をおこないます。
DOSプロンプトで、nssmを配置したディレクトリに移動し、nssm installコマンドを実行します。

コマンドを実行するとサービスインストーラのウィンドウがひらくので、必要な情報を入力します。
- Path:Apache Solrの起動コマンドパス
- Startup directory:ApacheSolrの起動ディレクトリ
- Arguments:起動パラメータ
- Service name:サービス名
以下のように入力します。
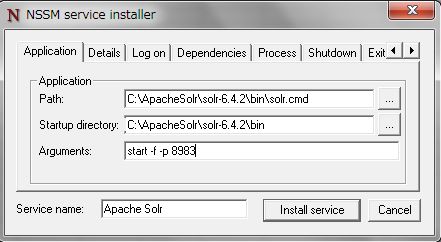
「Arguments」には、起動パラメータと同時に使用するポートを記載します。
筆者は、8983ポートを使用するようにしました。
全ての入力が完了したら、「Install service」ボタンを押下します。
以下のダイアログが表示されたらインストール完了です。
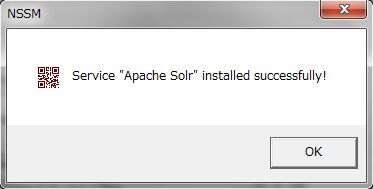
それでは、きちんとサービス化されたかどうかを確認してみましょう。
サービス一覧で「Apace Solr」が存在すれば、サービス化完了です。
「開始」を選択して、Apache Solrを起動してください。

ステータスが「開始」になったことを確認しましょう。
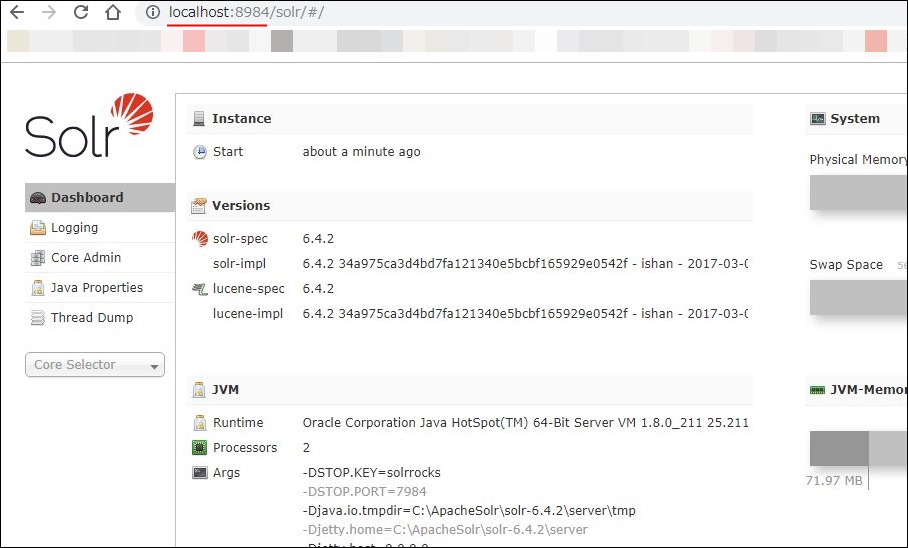
きちんと起動できたかを確認するためには、ブラウザでApache SolrのWeb画面を表示します。
ブラウザで入力するURLは「http://localhost:8984」です。
以下のようにダッシュボードが表示されれば、起動成功です。
コアを作成
Apache Solrの準備ができたら、Apache Solrで『コア』を作成して使用するための準備をおこないます。
『コア』とは何か?という説明は、いまは省略します。
とりあえず動かしたいので。
イメージとしては、データベースのスキーマでしょうかね?
コアの作成方法はいろいろあるみたいなのですが、筆者はDOSプロンプトでコマンドを実行する形でコアを作成します。
コアの名前は「java_sample」としました。

コアの作成が完了したら、Apache Solrのサービスを再起動します。
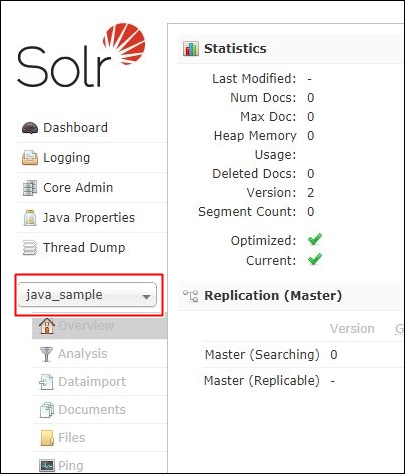
再起動後にダッシュボードを確認します。
「java_sample」というコアが作成されています。
コアを選択すると、ダッシュボードにコアの情報が表示されます。
これで、Apache Solrの準備完了です。
文書を登録
文書の登録を、JavaからAPIを実行する形でおこなうことが可能です。
サンプルプログラムは以下となります。
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.File;
import org.apache.solr.client.solrj.request.ContentStreamUpdateRequest;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.common.util.ContentStreamBase;
public class SolrInsert {
public static void main(String[] args){
System.out.print("start: main\r\n");
// idとファイル名をパラメータから取得
String id = args[0];
String fileName = args[1];
// Solrのインスタンス作成
SolrClient client = new HttpSolrClient.Builder(
"http://localhost:8983/solr/java_sample").build();
try {
// APIの実行準備
File file = new File(fileName);
ContentStreamUpdateRequest update =
new ContentStreamUpdateRequest("/update/extract");
update.addContentStream(
new ContentStreamBase.FileStream(file));
// idとファイル名をパラメータに指定
// 既に登録済のIDを指定した場合、登録ではなく更新となる
update.setParam("literal.id", id);
update.setParam("literal.filename", file.getName());
// コマンドを実行
client.request(update);
} catch (SolrServerException e) {
System.out.print("SolrServerException Occured!\r\n");
e.printStackTrace();
} catch (IOException e) {
System.out.print("IOException Occured!\r\n");
e.printStackTrace();
} finally {
try {
// コミットして、コネクションをクローズ
client.commit();
client.close();
} catch (Exception e) {
System.out.print("Exception Occured!\r\n");
e.printStackTrace();
}
}
System.out.print("end: main\r\n");
}
}
重要な部分は、強調表示している26行目から37行目の部分です。
実際にSolrに対して、「/update/extract」というAPIを呼び出して登録コマンドを実行しています。
メインとなる使用クラスは「ContentStreamUpdateRequest 」。「addContentStream」で電子ファイルの実態を指定し、setParamでパラメータを指定しています。
指定しているパラメータは2つで、IDとファイル名。
コメントにも記載していますが、同じIDを指定した場合はドキュメントの更新になります。
プログラムの動作結果を、ApacheSolrのダッシュボードで確認してみます。
まだ、1つドキュメントが登録されていない状態であれば、以下のようになります。
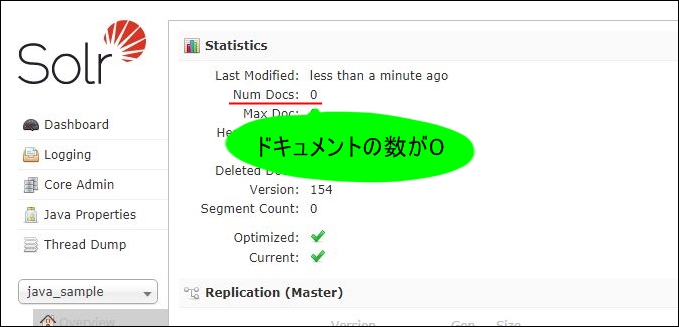
この状態でプログラムを実行してみます。
IDとファイル名はパラメータで指定可能となっていますが、IDは101、ファイル名はtemplate.xlsxを指定して、プログラムを実行します。
プログラムの実行後にコンソール画面を確認すると、ドキュメントが登録されていることが確認できます。
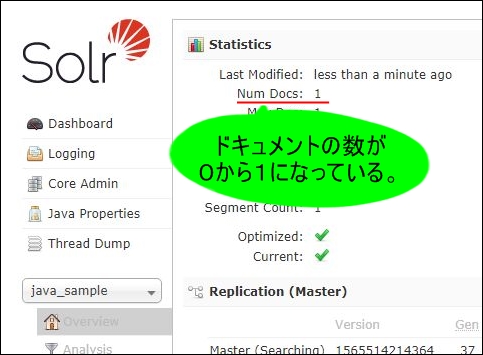
登録した結果を、もうちょっと詳しくみてみます。
Apache Solrのダッシュボードでは、ドキュメントの検索が可能です。
この検索を使って、登録したドキュメントを確認してみます。
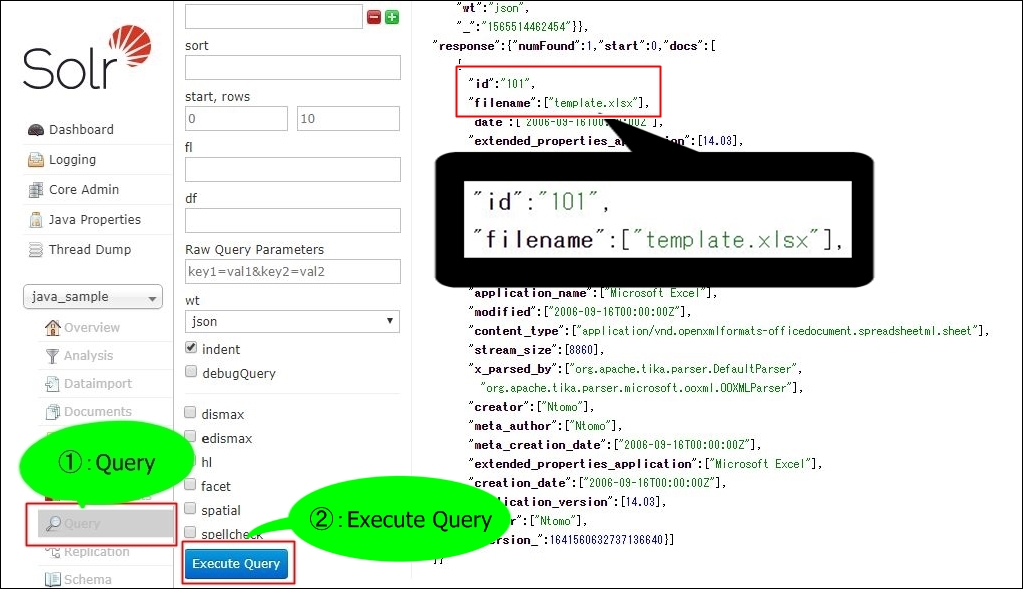
登録のときに指定したIDとファイル名のドキュメントが登録されていることがわかります。
次に「更新」をおこなってみます。
プログラムは「登録」の時のプログラムと同様です。
同じIDを指定すれば、Apache Solrが更新をおこなってくれます。
試しに、IDは登録の時に指定したIDと同じ「101」を指定し、ファイル名を「template_2.xlsx」に変更して、登録の時と同じプログラムを実行してみます。
実行した後に、Apache Solrのダッシュボードを確認すると、以下のようになります。
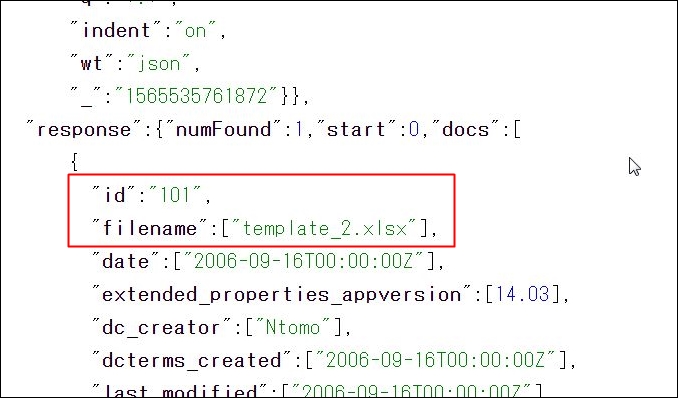
検索結果のドキュメント数は変わっておらず(numFoundが1)、id=101のドキュメントファイル名が、「template.xlsx」から「template_2.xlsx」に変わっています。
つまり、「登録」ではなく「更新」をおこなったことがわかります。
文書を全部削除
文書の削除もAPIから可能です。
まずは、全削除のAPIを作成して実行してみます。
削除するまえに、ApacheSolrにドキュメントを3つ登録してみました。
ApacheSolrのダッシュボードで、ドキュメントが3つ登録されていることを確認しておきます。
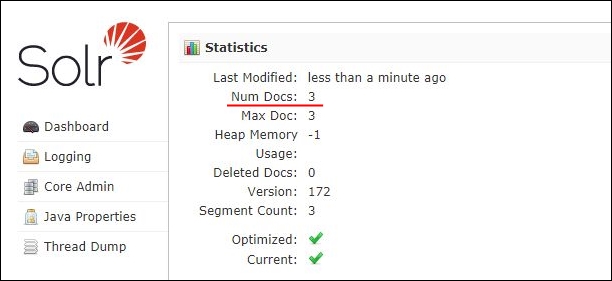
ドキュメントが3つ登録されていることが確認できました。
この状態で、ドキュメント全削除のプログラムを実行します。
サンプルプログラムは以下です。
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.File;
import org.apache.solr.client.solrj.request.ContentStreamUpdateRequest;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.common.util.ContentStreamBase;
public class SolrAllDelete {
public static void main(String[] args){
System.out.print("start: main\r\n");
// Solrのインスタンス作成
SolrClient client = new HttpSolrClient.Builder(
"http://localhost:8983/solr/java_sample").build();
try {
// APIを実行
String deleteQuery = "*:*";
client.deleteByQuery(deleteQuery);
} catch (SolrServerException e) {
System.out.print("SolrServerException Occured!\r\n");
e.printStackTrace();
} catch (IOException e) {
System.out.print("IOException Occured!\r\n");
e.printStackTrace();
} finally {
try {
// コミットして、コネクションをクローズ
client.commit();
client.close();
} catch (Exception e) {
System.out.print("Exception Occured!\r\n");
e.printStackTrace();
}
}
System.out.print("end: main\r\n");
}
}
実際の削除処理をおこなっている部分は、23行目と24行目になります。。
「SolrClient」クラスの「deleteByQuery」メソッドを使用して削除をおこなっています。
クエリパラメータに「*:*」を指定すると全削除、になります。
ApacheSolrのダッシュボードを確認するとドキュメント数が0になっており、全削除されていることがわかります。
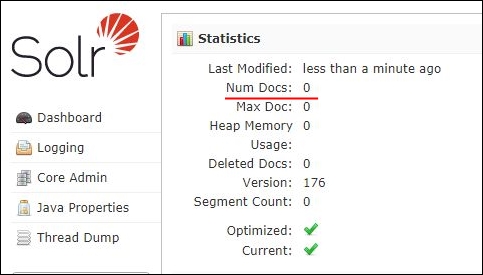
文書を一部削除
文書を全削除する方法を紹介しましたが、実際のシステムではあまりニーズはないかと思います。
あるとすれば、全削除ではなく指定したドキュメントのみを削除、ですかね。
指定したドキュメントのみを削除することも可能です。
サンプルプログラムは以下になります。
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.File;
import org.apache.solr.client.solrj.request.ContentStreamUpdateRequest;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.common.util.ContentStreamBase;
public class SolrOneDelete {
public static void main(String[] args){
System.out.print("start: main\r\n");
// Solrのインスタンス作成
SolrClient client = new HttpSolrClient.Builder(
"http://localhost:8983/solr/java_sample").build();
try {
// APIを実行
String deleteQuery = "id:(102)";
client.deleteByQuery(deleteQuery);
} catch (SolrServerException e) {
System.out.print("SolrServerException Occured!\r\n");
e.printStackTrace();
} catch (IOException e) {
System.out.print("IOException Occured!\r\n");
e.printStackTrace();
} finally {
try {
// コミットして、コネクションをクローズ
client.commit();
client.close();
} catch (Exception e) {
System.out.print("Exception Occured!\r\n");
e.printStackTrace();
}
}
System.out.print("end: main\r\n");
}
}
idが102のドキュメントを削除しています。
解り易いように、IDをハードコーディングしていますが、23行目と24行目です。
複数のドキュメントを削除する場合は、ID指定をORで繋いで指定すればよいです。
String deleteQuery = "id:(201 OR 202)";
client.deleteByQuery(deleteQuery);
文書を検索
次に文書の検索です。
ApacheSolrの肝となる部分ですね。
今回は「とりあえず動かす編」ということで、ファイル名での検索をおこないます。
本来であれば、登録したドキュメントの中身に対する検索をおこないたいところですが、それについてはまた次回、という事で。
今回は、とりあえず動かしちゃいましょう!
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.File;
import java.util.HashMap;
import java.util.List;
import java.util.Locale;
import java.util.Map;
import org.apache.solr.client.solrj.request.ContentStreamUpdateRequest;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.util.ClientUtils;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.client.solrj.response.Group;
import org.apache.solr.client.solrj.response.GroupCommand;
import org.apache.solr.client.solrj.response.GroupResponse;
import org.apache.solr.common.util.ContentStreamBase;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrDocument;
public class SolrSearch {
public static void main(String[] args){
System.out.print("start: main\r\n");
// Solrのインスタンス作成
SolrClient client = new HttpSolrClient.Builder(
"http://localhost:8983/solr/java_sample").build();
SolrQuery solrQuery = new SolrQuery();
// 検索結果として、文書IDを返却するよう設定
solrQuery.setFields("id");
// 検索結果の上限は100件
solrQuery.setRows(100);
try {
StringBuilder queryString = new StringBuilder();
String keyword = args[0];
if (keyword.equals("")) {
queryString.append("*");
} else {
String queryPhrase = "\"" +
ClientUtils.escapeQueryChars(keyword) + "\"";
queryString.append("(");
queryString.append("filename:");
queryString.append("*" + queryPhrase + "*");
queryString.append(")");
}
// 検索実行
solrQuery.set("q", queryString.toString());
QueryResponse response = client.query(solrQuery);
// 検索結果を表示
SolrDocumentList list = response.getResults();
if (list == null) {
System.out.println("文書は存在しませんでした。");
} else {
System.out.println(list.getNumFound() +
"件ヒットしました。");
for (SolrDocument doc : list) {
System.out.println(doc.get("id"));
}
}
} catch (SolrServerException e) {
System.out.print("SolrServerException Occured!\r\n");
e.printStackTrace();
} catch (IOException e) {
System.out.print("IOException Occured!\r\n");
e.printStackTrace();
} finally {
try {
// コミットして、コネクションをクローズ
client.commit();
client.close();
} catch (Exception e) {
System.out.print("Exception Occured!\r\n");
e.printStackTrace();
}
}
System.out.print("end: main\r\n");
}
}
まず、35行目と36行目で、返却するフィールドを定義しています。
このサンプルプログラムでは、「id」を返却するようにしています。
検索条件の設定部分は、47行目から51行目部分です。
サンプルプログラムでは、ファイル名を格納している「filename」フィールドに対して検索をおこなうようにしています。
あと、検索ワードはエスケープしています。
まとめ
いかがでしたでしょうか?
紹介した方法でApache Solrを構築してサンプルプログラムを実行すれば、といあえず一連の動作は動きます。
しかし、ApacheSolrの醍醐味はやっぱり検索です。
ApacheSolrの検索には、いろいろなオプションが存在しますので、次回の記事でそこら辺を紹介していきます。
それではまた!


