
前回、「Standard Highlighter」を使ったドキュメント検索、および、ハイライトを紹介しました。

今回は、ハイライト表示をおこなうことができる別の方法である「FastVector Highlighter」の使用方法を紹介します。
目次
環境情報
環境情報は以下になります。
使用するのは、JavaとApache Solrの2つのみです。
- Java 12.0.1
- ApacheSolr 6.4.2
設定変更
「Standard Highlighter」でのハイライト表示をおこなった後に、「FastVector Highlighter」を使えるように設定変更をおこないます。
「Standard Highlighter」のスキーマ定義については、前回の記事を参考にしてください。
「Standard Highlighter」を使っている状態から、「FastVector Highlighter」を使える状態に変更します。
まずはスキーマ定義です。
今回は、文書の中身に対して検索をおこない、検索結果をハイライト表示することを想定します。
文書の中身を格納するフィールドである「content」について、以下のように設定変更をおこないます。
変更するファイルは「managed-schema」です。
<field name="content" type="text_general_content" multiValued="false" indexed="true" stored="true"/>
以下のように変更します。 ↓↓↓
<field name="content" type="text_general_content" multiValued="false" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true"/>
3つの設定値について、「true」を設定しています。
|
フィールド名 |
設定値 |
説明 |
|
termVectors |
true=設定する false=設定しない |
検索キーワードが含まれる数やキーワードの開始、終了位置などを結果に含めるかどうか(termPositionsとtermOffsetsをtrueに設定した場合、termVectorsもtrue扱いとなる) |
|
termPositions |
true=設定する false=設定しない |
検索キーワードの含まれる位置を返すかどうか |
|
termOffsets |
true=設定する false=設定しない |
検索キーワードの含まれる位置を返すかどうか |
変更したら、Apache Solrのサービスを再起動して、変更した内容がコア定義に反映されているかを確認します。
Apache Solrのダッシュボードをひらき、コアの選択で対象コアを選択します。
コアを選択したら、左ペーンで「schema」を選択し、「content」フィールドを確認します。
「TermVector Stored」「Store Offset With TermVector」「Store Position With TermVector」が表示されチェックされていれば、スキーマの設定変更OKです。
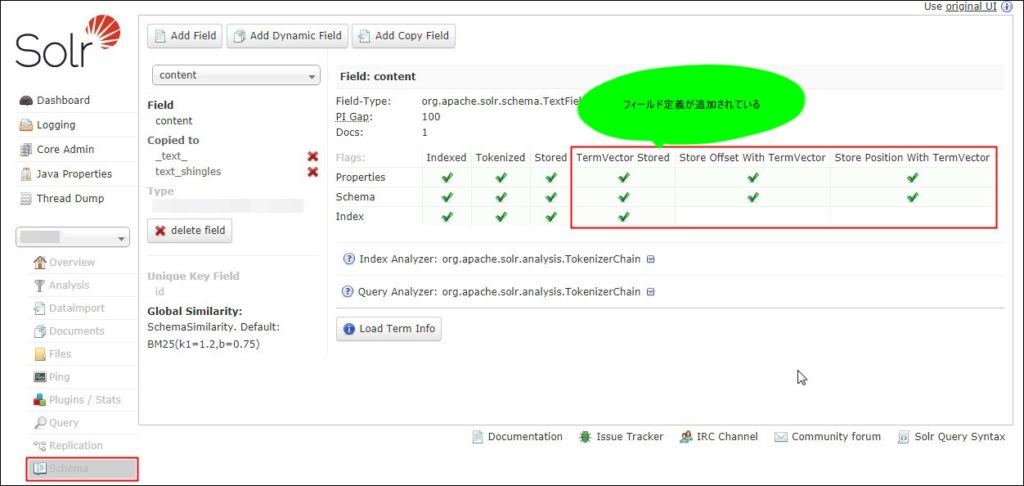
筆者は、この定義をおこなうことで「FastVector Highlighter」でのハイライト表示について思ったような結果が返却されるようになりました。
今回は、「Standard Highlighter」を使ったハイライト表示とまったく同じ結果にすることを目標にします。
その場合、ハイライト表示する際に検索ワードを囲むHTMLタグを固定させてしまおうと思います。
その場合、以下の定義変更が必要になります。
変更するファイルは「solrconfig.xml」です。
<fragmentsBuilder name="colored" class="solr.highlight.ScoreOrderFragmentsBuilder">
<lst name="defaults">
<str name="hl.tag.pre"><![CDATA[
<b style="background:yellow">,<b style="background:lawgreen">,
<b style="background:aquamarine">,<b style="background:magenta">,
<b style="background:palegreen">,<b style="background:coral">,
<b style="background:wheat">,<b style="background:khaki">,
<b style="background:lime">,<b style="background:deepskyblue">]]></str>
<str name="hl.tag.post"><![CDATA[</b>]]></str>
</lst>
</fragmentsBuilder>
↓↓↓
<fragmentsBuilder name="colored" class="solr.highlight.ScoreOrderFragmentsBuilder">
<lst name="defaults">
<str name="hl.tag.pre"><![CDATA[<b>]]></str>
<str name="hl.tag.post"><![CDATA[</b>]]></str>
</lst>
</fragmentsBuilder>
「hl.tag.pre」について、<b>タグのみを使用するように変更します。
こうすることにより、検索ワードをbタグで囲みます。
こんな感じです。
- <b>検索ワード</b>
FastVector Highlighterのサンプルコード
「FastVector Highlighter」を使った検索のサンプルコードは以下になります。
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.File;
import java.util.HashMap;
import java.util.List;
import java.util.Locale;
import java.util.Map;
import org.apache.solr.client.solrj.request.ContentStreamUpdateRequest;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.util.ClientUtils;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.client.solrj.response.Group;
import org.apache.solr.client.solrj.response.GroupCommand;
import org.apache.solr.client.solrj.response.GroupResponse;
import org.apache.solr.common.util.ContentStreamBase;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrDocument;
public class SolrSearchFast {
public static void main(String[] args){
System.out.print("start: main\r\n");
// Solrのインスタンス作成
SolrClient client = new HttpSolrClient.Builder(
"http://localhost:8983/solr/java_sample").build();
SolrQuery solrQuery = new SolrQuery();
// 検索結果として、文書IDを返却するよう設定
solrQuery.setFields("id");
// 検索結果の上限は100件
solrQuery.setRows(100);
try {
StringBuilder queryString = new StringBuilder();
String keyword = args[0];
if (keyword.equals("")) {
queryString.append("*");
} else {
String queryPhrase = "\"" + ClientUtils.escapeQueryChars(keyword) + "\"";
queryString.append("(");
queryString.append("content:");
queryString.append(queryPhrase);
queryString.append(")");
}
// 検索実行
System.out.println("q=" + queryString.toString());
solrQuery.set("hl.useFastVectorHighlighter", "true");
solrQuery.set("hl.fragmentsBuilder", "colored");
solrQuery.set("hl", true);
solrQuery.set("hl.fl", "content");
solrQuery.set("hl.fragsize", 100);
QueryResponse response = client.query(solrQuery);
// 検索結果を表示
SolrDocumentList list = response.getResults();
if (list == null) {
System.out.println("文書は存在しませんでした。");
} else {
System.out.println(list.getNumFound() + "件ヒットしました。");
// ハイライト情報を取得して加工
Map<String,Map<String,List<String>>> highlighting = response.getHighlighting();
for (SolrDocument doc : list) {
System.out.println(doc.get("id"));
String id = (String) doc.getFieldValue("id");
Map<String, List<String>> map = highlighting.get(id);
List<String> contentList = map.get("content");
for(String val : contentList) {
val = val.replaceAll("[\r\n\t]", "");
System.out.println("val=" + val);
}
}
}
} catch (SolrServerException e) {
System.out.print("SolrServerException Occured!\r\n");
e.printStackTrace();
} catch (IOException e) {
System.out.print("IOException Occured!\r\n");
e.printStackTrace();
} finally {
try {
// コミットして、コネクションをクローズ
client.commit();
client.close();
} catch (Exception e) {
System.out.print("Exception Occured!\r\n");
e.printStackTrace();
}
}
System.out.print("end: main\r\n");
}
}
「Standard Highlighter」を使ったハイライト表示をおこなうサンプルコードと、ほぼほぼ同様です。
違う箇所は、クエリパラメータだけ。
検索結果のハイライト文字列についても、「Standard Highlighter」を使用したサンプルコード検索結果と、ほぼ同様となります。
「Standard Highlighter」と「FastVector Highlighter」、どっちを使うべきか?
どちらを使っても同じハイライト表示をおこなうことができるので、機能としては同等です。
では、どちらを使った方がいいのか?ということですが、筆者は「FastVector Highlighter」を推します。
理由はパフォーマンスです。
筆者が検証した限りでは、「Standard Highlighter」と「FastVector Highlighter」では、約5倍の性能差がありそうです。
以下は、500ファイルが登録されたコアに対して、30ファイルがヒットする状態に対してのパフォーマンス比較です。
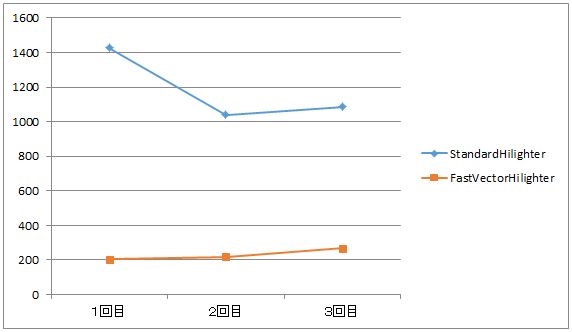
縦軸はmsecです。
なので、「Standard Highlighter」が1秒ちょっとかかる検索に対して、「FastVector Highlighter」は0.2秒くらい。
パフォーマンスが圧倒的に違います。
こうなってくると、「FastVector Highlighter」を使った方がよいという話になります。
では、「FastVector Highlighter」を使うデメリットはまったくないかというとそうではないです。
「設定変更」で説明したスキーマ定義をおこなうと、ファイルを登録した際にコアに登録されている内容が変わってきます。
コアのファイルサイズが、変更前のスキーマ定義と比べると1.5倍になりました。
あまり深く調べられてまとめいないのですが、「termVectors」「termPositions」「termOffsets」をオンにすると、「FastVector Highlighter」を使うためのインデックス情報をApacheSolrが大量に作るようです。
そのために、ファイルサイズが膨大になるが、高速な検索が可能になるということなります。
まとめ
いかがでしたでしょうか?
「FastVector Highlighter」について説明してきましたが、前記事の「Standard Highlighter」と比べると違いがわかるかと。
- 「Standard Highlighter」ではなく「FastVectorHighlighter」を使った方が高速
- でも、「Standard Highlighter」より「FastVectorHighlighter」の方がディスク使用率が高い
結論としては筆者は「FastVector Highlighter」推しです。
やはり、検索パフォーマンスが高いのは魅力的なので。
それではまた!


